Our Early Journey to Transform Instacart's Discovery Recommendations with LLMs

Key Contributors: Moein Hasani, Hamidreza Shahidi, Trace Levinson, Guanghua Shu
Introduction
At Instacart, we are laser-focused on improving the user experience by making shopping feel easy, engaging, and personalized. Our discovery surfaces play a central role in bringing this to life. Alongside explicit Search intents, discovery is our opportunity to meet customers’ implicit needs, presenting them with the most relevant and inspiring content we have to offer. The main discovery surface within the Instacart app, referred to here as the “Shopping Hub”, is one of the most critical in this regard. This is the surface a customer lands on within the Instacart app after selecting their desired retailer, guiding them along their entire journey. What users see here shapes not just what they buy, but how intuitive and enjoyable their experience feels.
Given its importance, our team runs dozens of Shopping Hub experiments per year, constantly evaluating new ways to enrich the discovery experience. Historically, these experiments have been constrained by static content libraries feeding our recommendation systems.
With the rapid advancement of generative AI, a critical opportunity began to emerge: rather than incrementally improving a swath of legacy systems, could we leverage LLMs to rethink how content shows up for a user from the ground up? Which new primitives could we build to uplevel quality, personalization, and cohesion across the page?
This blog post walks through our early journey to answer these questions. By investing in a new AI-native platform for content generation, evaluation, and retrieval, we have found generative models to show real promise in improving recommendations at scale. Below, we highlight the approach we took in developing this platform, a few key learnings so far, and where we’re most bullish moving forward.
Limitations of Traditional Recommendation Engines
Our Shopping Hub page is constructed from multiple subcomponents called placements. Each placement contains a number of products or other entities within it. The example below can help us visualize how these various pieces ladder up to the full page.
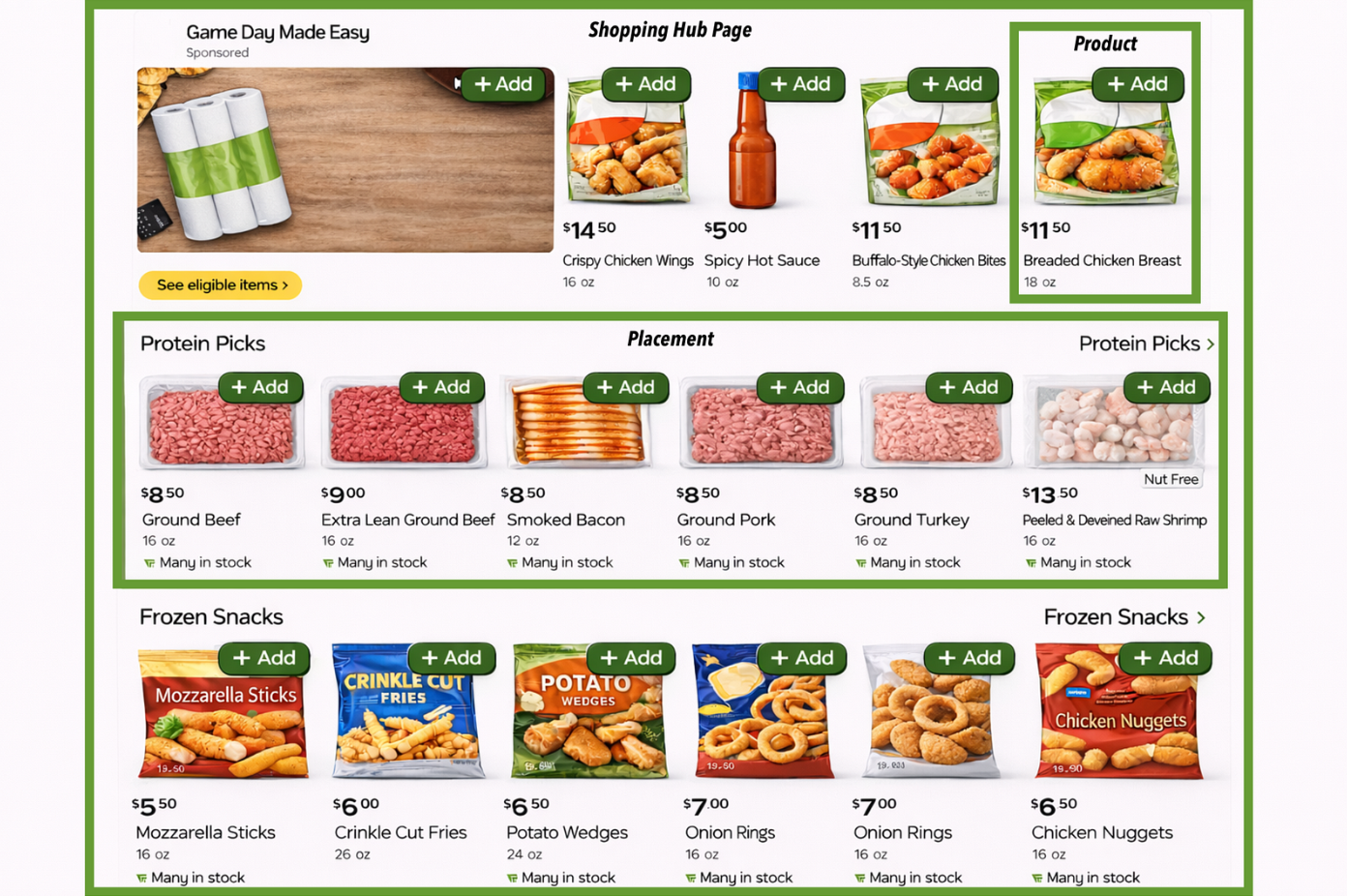
Today, the flow to generate and serve Shopping Hub content looks something like the following:
- Text, visual assets, and the underlying retrieval sources for a new placement are defined explicitly. Titles are often generic, such as “Dairy”, with a narrow set of retrieval sources used to fetch corresponding products. Once created, each placement enters the content library and becomes eligible for serving, universally, across all users. This generation process is human-driven and inherently assumes a one-size-fits-all content library that applies to all users.
- Retrieval systems fetch these candidate placements and corresponding products at runtime.
- From the retrieved set, ranking models order products and placements across the page to optimize against a static set of business metrics. Each placement is treated as an independent entity on the page within ranking models.
This setup can perform well for optimizing average engagement under the above constraints. However, the reality is that different users have different needs on the platform, and business objectives and the broader environment are constantly changing. This results in a couple of key limitations for our recommendations:
- Difficulty in scaling personalized content: The human-driven process above is expensive and time-intensive, with teams managing both generation and content QA by hand. As a result, traditional architectures inhibit the ability to quickly deploy and personalize new content — not only per user, but also according to seasonal and other shifting dimensions and business objectives.
- Lack of cohesion: Placements are often created by different siloed teams with divergent focus areas and goals. As a result, the series of placements can result in a chaotic surface presentation. Users are required to scroll without the ability to easily navigate the page to solve their needs.
So, where does AI come in?
Large language models offer a natural mechanism for producing cohesive, dynamic, and personalized output. We began to explore ways to tackle the above limitations by introducing generative models into our recommendations stack. To narrow down our approach, we first began thinking through objectives for the system to ensure any solution would be anchored to North Star principles.
- Delightful Personalization: The system should be capable of leveraging our rich user data to meet users where they are on the platform. One user may be health-conscious and focused on soups and salads. Another user looks to Instacart for home improvement goods and other category needs beyond only food and drinks. Given the diverse reasons our customers turn to Instacart, our primary motivator for the work was to enable rich, delightful experiences for every customer on our platform, rather than solving for averages. This may also include very different products retrieved for the same intent — a thematic “Breakfast” placement may prioritize waffles and pancakes for one user, but granola and yogurt for the other.
- Cohesion: The system should enable full cohesion across the page — every placement should be intentionally grouped, ordered, and aware of others around it. We want the discovery journey to feel seamless.
- Adaptability: The system should be responsive to rapid adjustments as our business environment shifts. This includes support for varying business objectives, such as relevance versus novelty, as well as temporal dimensions such as seasonal winter placements that can be spun up dynamically as they become relevant, then phased out.
With these guiding principles, we narrowed consideration down to two core generative paradigms:
- Bottoms-up generation: Directly generate all possible products to serve to a user, then cluster and organize them into placements.
- Top-down generation: Begin by generating ordered placements to structure the entire page, then generate products per placement.
To visualize this distinction, let’s take a simple example and assume we are building two placements to recommend to a user. Generative models can compose the problem in one of two ways:
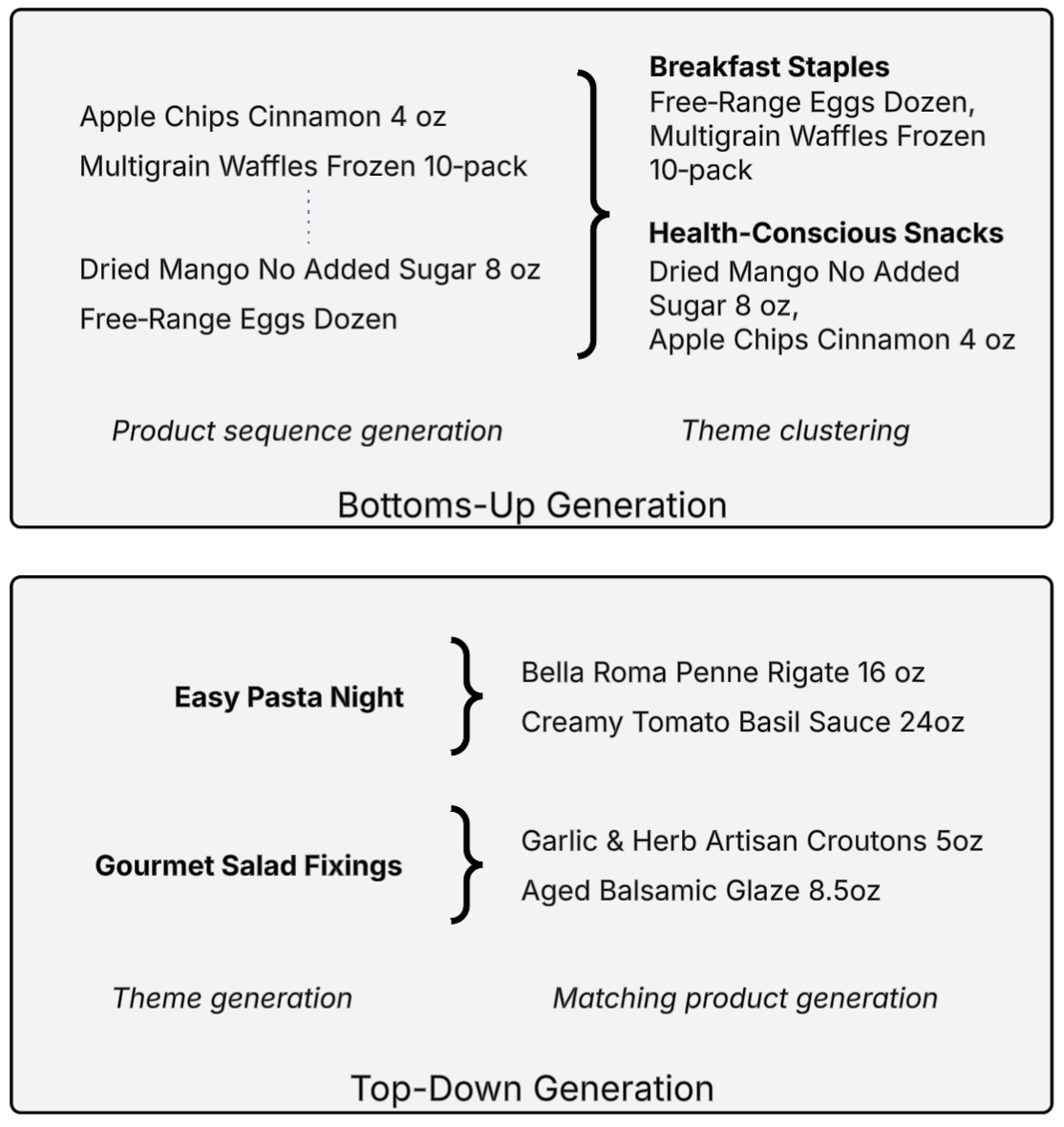
In the bottoms-up approach, a model generates a raw sequence with all relevant products, then clusters those products into Breakfast Staples and Health-Conscious Snacks themes.
Under the top-down approach, Easy Pasta Night and Gourmet Salad Fixings themes are first generated and ordered to meet user relevance, cross-theme cohesion, and other business goals. Products are then generated to map to each theme.
Comparing the two methods for our use case
The bottoms-up approach contains interesting benefits, such as deep flexibility with less constrained recall. However, it also presents difficulties in real-world settings due to latency requirements and catalog turnover. Further, with a much broader modeling task, it can be difficult to ensure generated products meet a diverse set of page requirements and intents, and may require significant fine tuning efforts as needs evolve. In other words, while the first two tenets could be achieved, we felt our adaptability goal would be put at risk. To best balance personalization, cohesion, and adaptability, we landed on a top-down, cascaded approach.
Methodology
After landing on the top-down approach, our next question was how exactly to decompose the problem. In early explorations, we evaluated the possibility of an all-in-one model that would directly generate placement content from raw signals. We started with this approach for simplicity, but ultimately found great value in decomposing generation into multiple targeted tasks. This opened the door to using retrieval‑augmented generation (RAG) and other techniques that aren’t feasible in a single‑step model, enabling us to achieve higher quality while improving cost efficiency.
Overview
The system consists of a few main phases:
- Page design & theme generation
- Retrieval keyword generation
- Quality and diversity filtering
- Product and pagewise ranking
The first three phases form our generative content pipeline, while the final phase leverages existing ranking infrastructure for scalable serving.
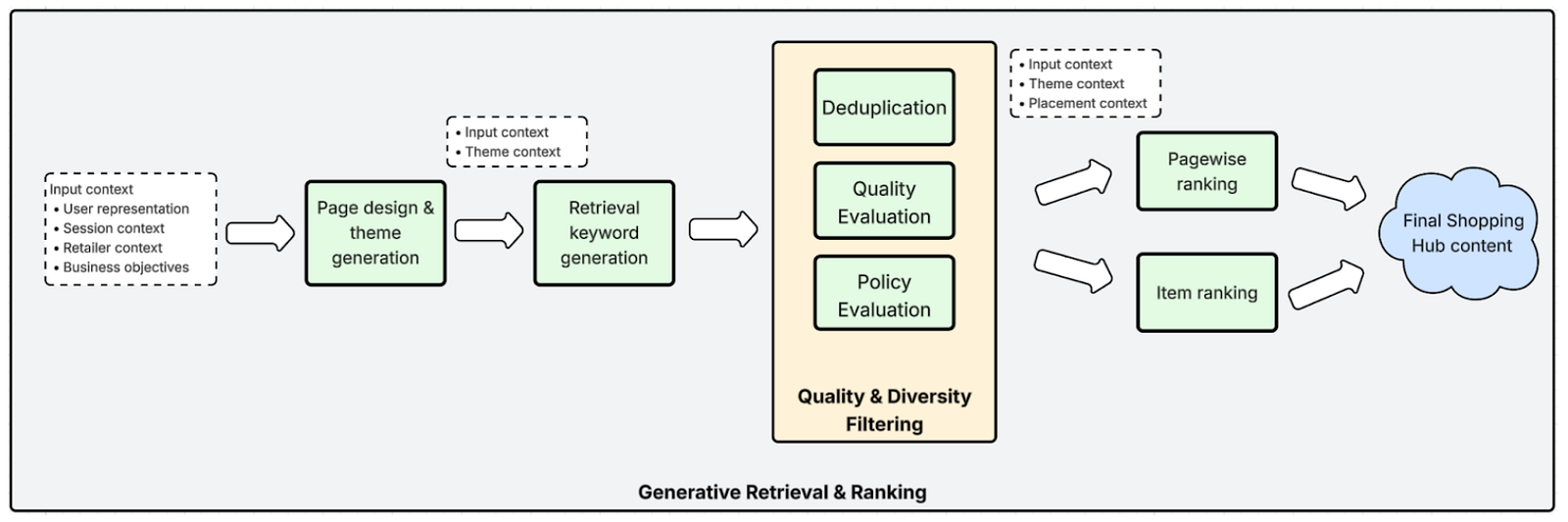
Over the next few sections, we’ll walk through each of these components in detail and how they ladder up to the final Shopping Hub users see on the platform.
Phase 1: Page Design & Theme Generation
First, a page design agent leverages user context (purchase history, engagement signals, and other derived preferences) to produce a set of high-level themes personalized to each user. Themes are designed to represent discrete and coherent shopping intents (for example, “Flavor builders for weeknight meals” or “Functional hydration, lower sugar”). We leverage constrained decoding with a structured schema to ensure interpretability and downstream usability.
To optimize downstream token efficiency, Phase 1 outputs both placement entities as well as a set of derived signals, such as user personas and freeform product concepts that align well with user context and placement intent. This removes the need for redundant context passthrough along each stage of the pipeline.
Phase 2: Retrieval Keyword Generation
Once generated in Phase 1, each theme is mapped to one or more retrieval-compatible descriptors (ex: search query strings, categories from our catalog taxonomy, product attribute filters). We explored various descriptor representations and ultimately found structured, taxonomy-grounded representations to perform best in upholding relevance. For simplicity, we will refer broadly to these descriptors as keywords here.
Teacher-Student Fine Tuning
To meet latency and cost requirements, we leveraged teacher–student learning: a closed-weight LLM first generates high-quality supervised data, validated on a small sample by human annotators. An LLM judge is then used to prune poor-quality data from our fine-tuning dataset, and an internal model is fine-tuned to imitate the teacher while satisfying domain-specific constraints.
Finally, we performed a number of ablation studies to converge toward the optimal student model:
- Open-weight base model explorations across the Llama and Qwen families
- LoRA adapter addition at varying ranks
- Finetuning sample size augmentation
RAG
To further improve prompt efficiency while maintaining strong precision, we incorporated retrieval-augmented generation (RAG) into the keyword generation pipeline. First, the page design LLM in Phase 1 generates freeform product concepts, such as “eggs”, from its universal knowledge base that align well with user context and placement intent. Embeddings are generated for these concepts. In the keyword generation model, we then restrict eligible candidate keywords per theme using embedding‑based similarity. Roughly 100 nearest neighbors are retrieved from a 300,000‑term keyword corpus, and only this refined subset is passed down for the second LLM to select from as final recommendations. This first-pass candidate pruning reduces input context significantly in the second LLM, reducing all-in generation costs by 15–20% in each generation. This became a core motivator for adopting a cascaded generation architecture. A single‑LLM setup would instead require the full keyword corpus to be passed directly into the prompt to maintain the same level of precision.
Phase 3: Quality and Diversity Filtering
Given the dynamic nature of this system, guardrails help to prevent cross-placement redundancies and ensure high-quality content. The system handles this in a few stages:
- To ensure sufficient diversity, embeddings are generated for each placement’s content, and similarity-thresholded deduplication is applied to remove redundant placements.
- For broad quality validation, LLM-as-a-judge workflows are deployed against a small proportion of users to ensure overall theme quality and brand compliance. Theme-product relevance is then enforced through a fine-tuned cross encoder, which explicitly classifies the relevance of each placement’s products to their overarching theme. Low-scoring entries are flagged for offline filtering or repair before serving deployment. Our full suite of evaluators is described in more detail in the Evals section below.
- Finally, additional guardrails kick in to enforce business and policy constraints. For example, we should ensure all original business objectives from agent instructions are addressed. Furthermore, it is critical to ensure themes do not misalign with Instacart’s brand, or even hallucinate with harmful or inappropriate pairings like alcoholic products for a child’s birthday party.
Phase 4: Product & Pagewise Ranking
Finalized placements and keywords are cached for runtime retrieval. Existing product and placement ranking services retrieve all generated entities, perform additional ranking and post-processing, and return finalized ordered entities on the page. This design modularizes the system, decoupling generative retrieval from mature ranking systems and providing a path to deeper pagewise control as the generative component matures.
Designing for Rapid Iteration: Treating Evals as a First-Class Citizen
When developing any AI-native system, particularly one that generates dynamic content served to millions of users, quality enforcement is essential. Potential for off-brand or other low-quality content can quickly degrade trust with our customers, so our team invested deeply in designing a robust suite of LLM-based and other evaluators, enabling us to iterate with confidence. This not only helped us derisk adverse behavior; it also became a massive accelerant. Given the vast exploration space for generative recommendations, online iteration would be slow, variance-prone, and cost-prohibitive. After a temporary slowdown upfront, the benefits of our QA investments have begun to compound across both velocity and output quality.
Below, we’ll walk through our three-pronged Eval framework:
- LLM-as-a-judge evaluators
- Fine-tuned QA at scale
- Traditional ML and metric-based evaluators
LLM-as-a-Judge
First, a rich suite of LLM-as-a-judge evaluators audits output along each level of the content hierarchy. Quality is graded along dimensions such as the following:
At the page level:
- Does the page feel cohesive enough? Diverse enough?
- Does the full set of generated placements cover all of our business needs?
At the placement level:
- Are the titles of high quality and aligned with our brand?
- Do placement themes align with user preferences and order behavior?
At the product level:
- Have we maintained sufficient product recall in the final output?
- Are the underlying retrieval keywords and products still aligned with the title’s thematic intent?
To build trust in this framework, we developed a series of human-in-the-loop (HITL) workflows to build ground truth data, tuning the LLMs until passing high human-alignment thresholds.
Unlocking Evaluation at e-Commerce Scale
LLM-as-a-judge evaluators are a powerful tool. However, we found that while this framework guided us well at the averages, it failed at the edges. Since evaluating millions of candidates is cost-prohibitive, LLMs are unable to take action and improve quality at scale. Certain quality dimensions hit diminishing returns, such as preserving end-to-end model context: final products retrieved did not always align well with the placement’s upstream thematic intent.
Given this insight, we made the decision to supplement Evals with a fine-tuned DeBERTa model, classifying product-title relevance for every generated placement. This model is trained on the same HITL ground truth data generated for LLM-as-a-judge evaluators, synthetically augmented for broader teacher-student model learning.
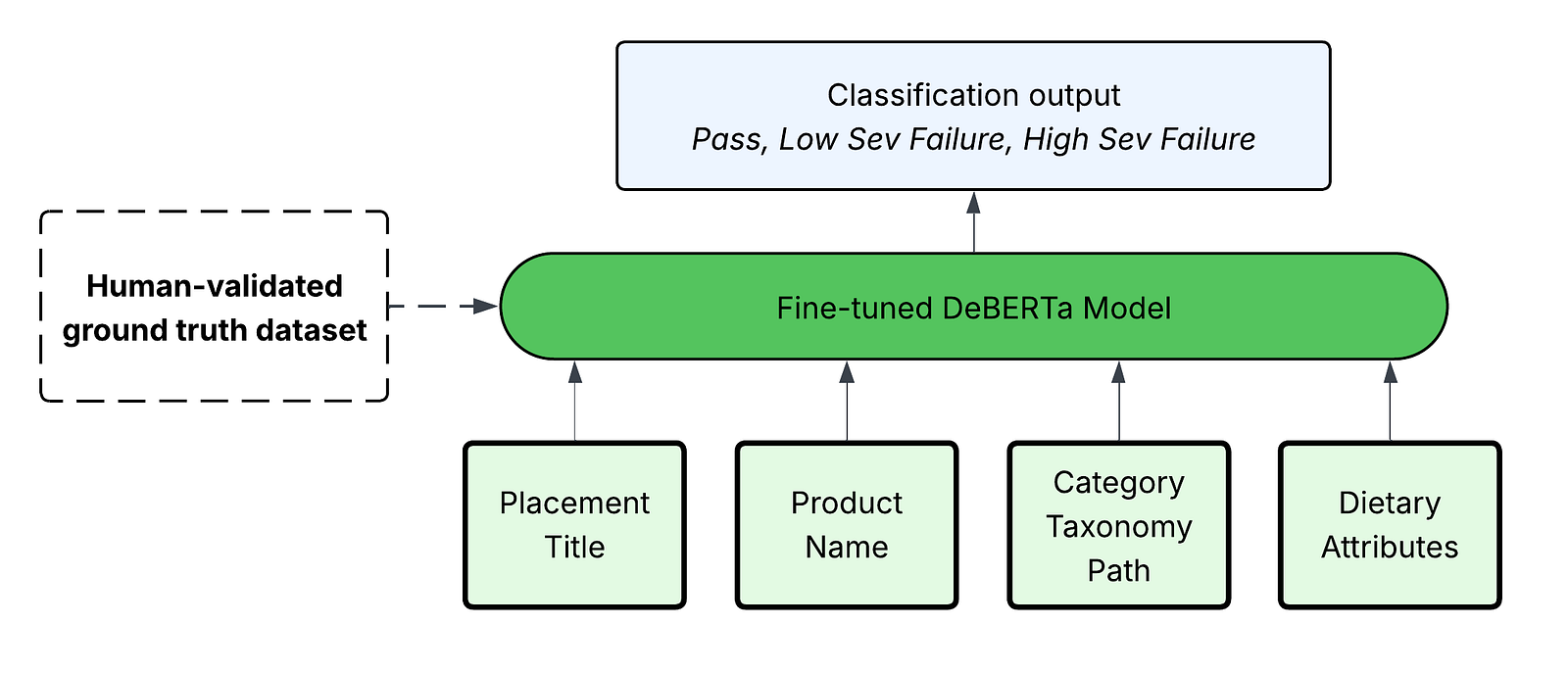
This model unlocked over a 99% cost reduction relative to closed-weight LLM inference. This enabled us to leverage it not only for evaluation, but also for full-scale quality filtering, where any placements classified as a severe violation are pruned before deploying to production.
Classical ML and Metric-Based Evaluations
Lastly, we rounded out the suite with a number of classical ML and metric-based evaluators. These span both explicit and derived signals already built for other use cases. We have found these to be useful proxies for broad relevance and quality:
- Average proportion of products represented in the user’s purchase history
- Predicted user-product engagement scores from our existing ranking models
- Average products per placement (density)
Bringing the Pieces Together
Let’s see how the above pieces come together with a more detailed view of our content generation & evaluation architecture:
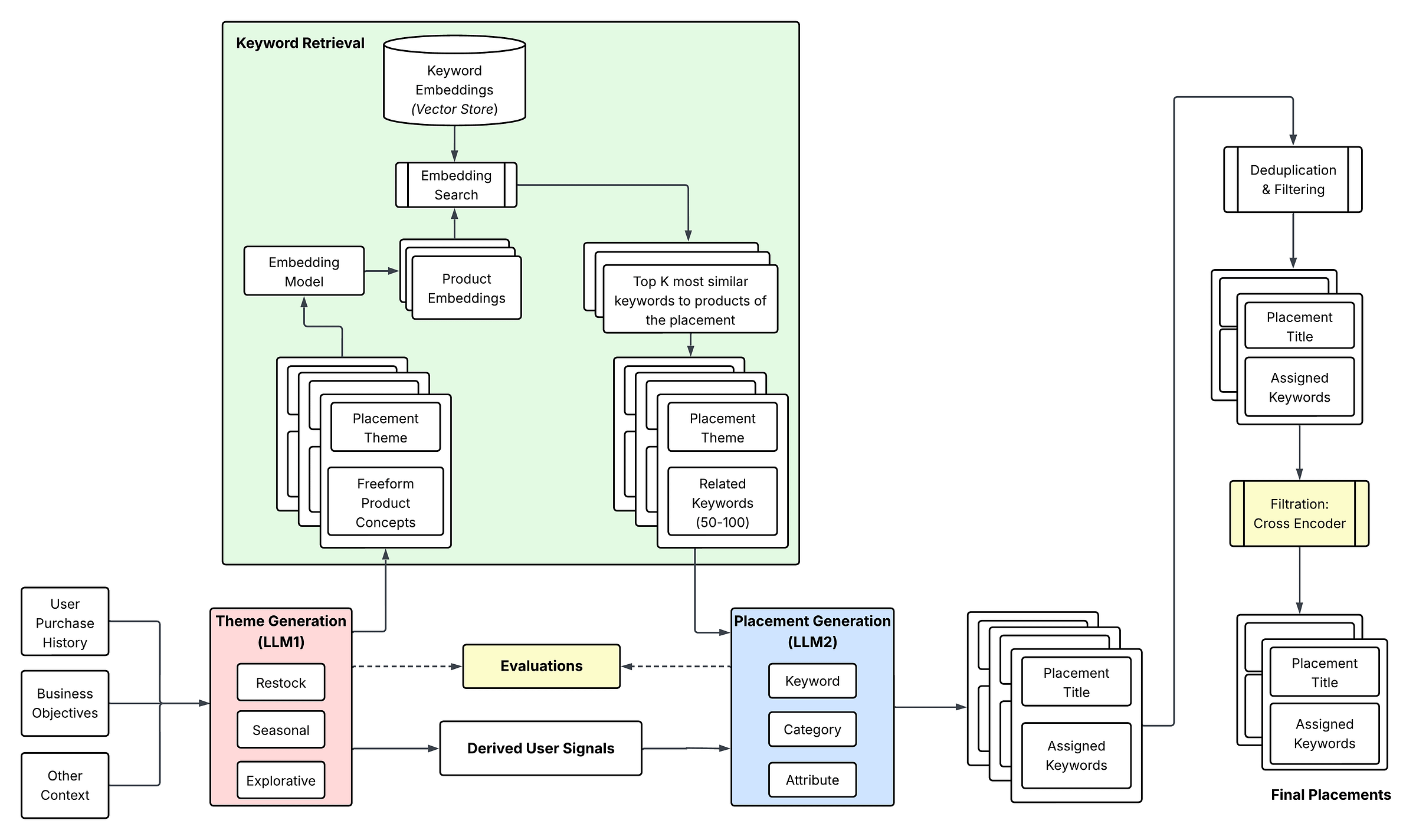
Results
This generative merchandising framework leads to a meaningful shift in placement composition. A sample of static vs. AI-generated placements for the same user can be seen in Figures 2a and 2b below. Compared to rigid single-category placements, generative placements tie closely to the user’s shopping history and build engaging themes composed of several underlying categories (e.g. meats, cheeses, and breads).
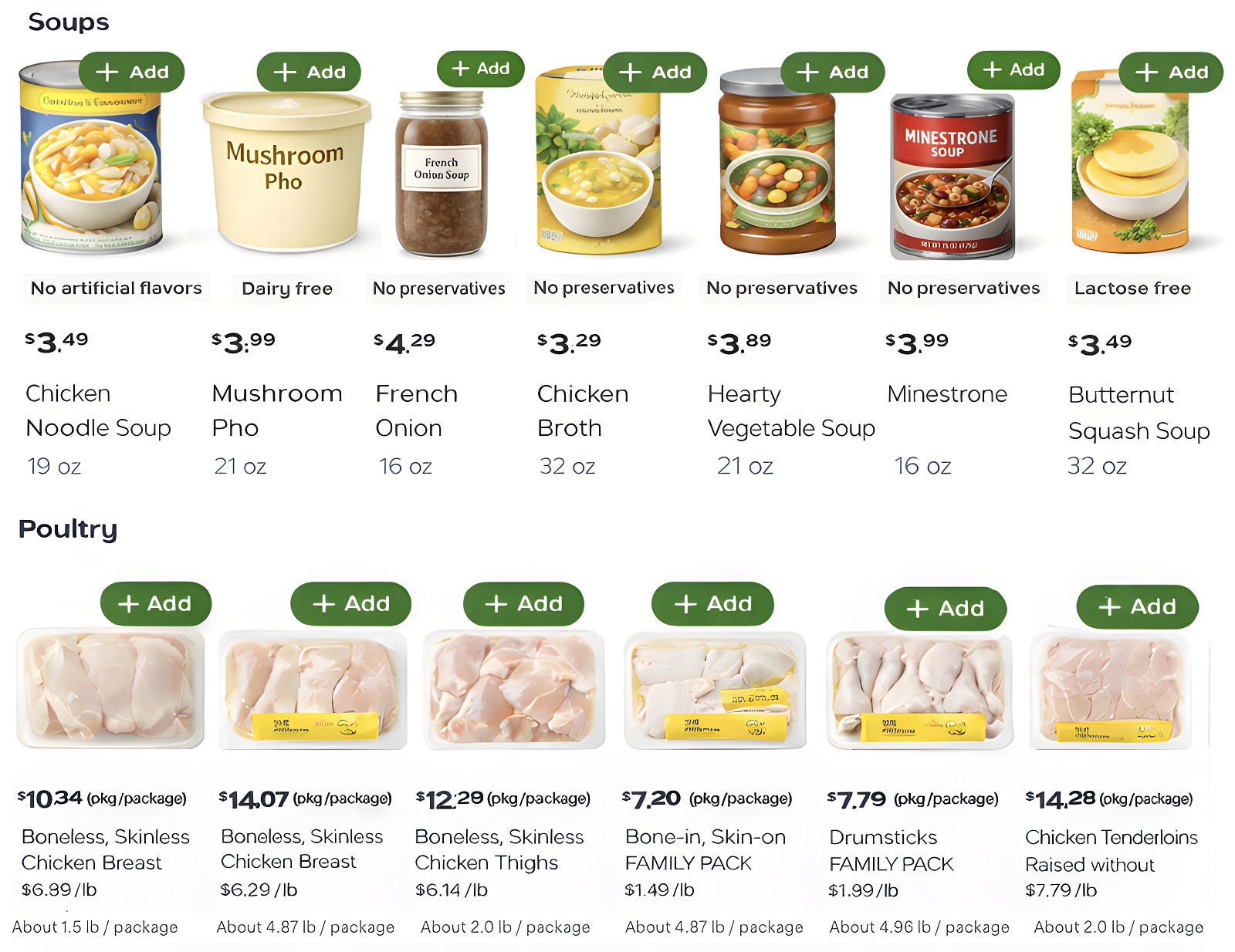
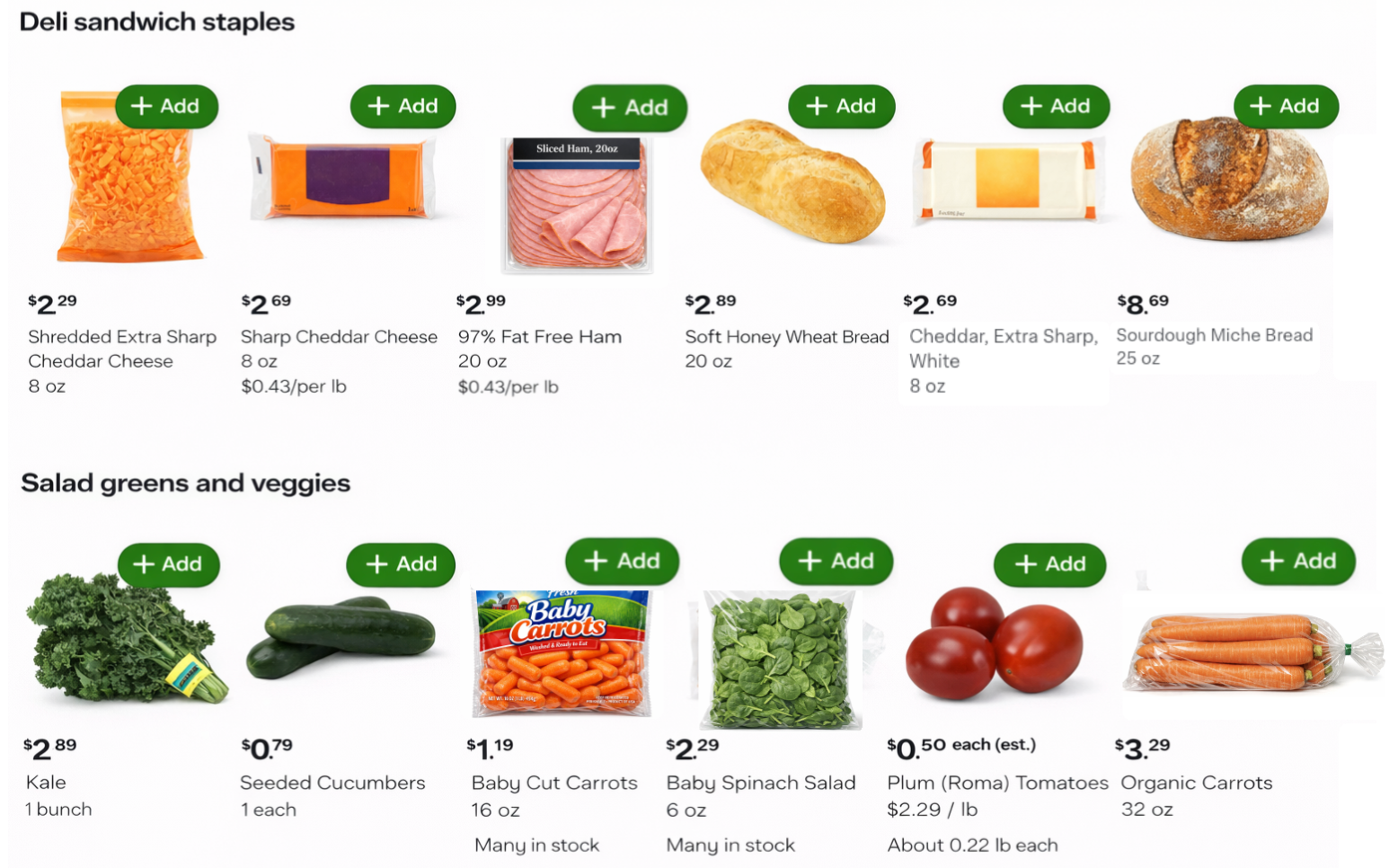
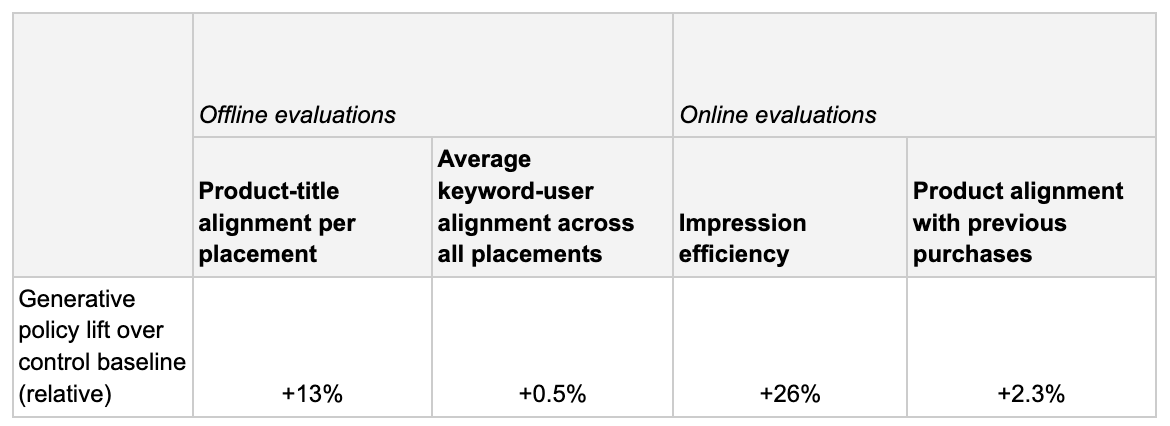
Amongst dozens of iterations, we began to observe generative policies outperform our baseline in offline evaluations. This validation finally built the level of confidence needed to perform large-scale A/B experiments comparing the generative page to the production baseline. While work remains to enable us to fully overhaul our prior systems, initial results have been quite promising.
Key Learnings
Over the course of this work, we have taken away broad learnings that we hope can be valuable to other AI developers.
Keep each modeling task focused: Models perform best with a well-defined task. While all-in-one workflows are tempting when working with frontier models, we have found stronger, more easily tunable performance by decomposing into multiple tasks. This became most evident in our fine-tuning efforts — smaller models required a high level of handholding in sample data and label definitions to reach strong performance.
Evals are worth the pain: It is difficult to overstate the value Evals provided in this work. Building comprehensive and human-validated LLM judges is admittedly a daunting task when kicking off a new project. But particularly for domains with highly variable output, such as personalized recommendations, a clear quality definition helps to prevent paralysis later on. We consistently steered our generation strategy to make progress against the evaluators we had set up.
Adding structure to input and output layers meaningfully improves outcomes: A number of optimizations to our inference data flows were impactful in bringing this system to production. Efficient context handling — especially through RAG and aggressive token compression — unlocked richer input signals without ballooning cost. In the output layer, constrained generation ensures the model always produces reliable, production‑safe outputs. Together, these examples speak to a broader principle: well-structured flows lead to more dependable and scalable agentic systems.
Looking Forward
We are just getting started on this platform. Moving forward, we will expand the system to balance multiple objectives, such as relevance and novel inspiration, and introduce deeper personalization through real-time and sparse signals. We are also exploring reward modeling and reinforcement fine tuning (RFT) to enable self-improvement with tight feedback. An exciting direction here will be learning how our stack of traditional ranking models can be fused as reward models within post-training, bringing recommendations fully into the generative paradigm.
In parallel, our teams are also exploring how to scale generative recommendations to surfaces beyond the Shopping Hub, such as landing pages and Search results. Early experiments are showing promising signs — stay tuned!
Acknowledgements and Final Notes
We would like to extend deep gratitude to our cross-functional partners Dhruv Khanna, Logan Murdock, Roy Li, Aref Kashani, Shayaan Nadeem, Amish Popli, Lauren Downey, Shrikar Archak, Brett Brownell, and Brandon Silberstein, who have provided critical ongoing design feedback and driven system integrations to bring this research to production. Vinesh Gudla, Hechao Sun, Jingying Zhou, and Tejaswi Tenneti also made meaningful contributions in our early stages of development. Additional thanks to Pramod Adiddam and Venkatesh Shankar for steady leadership and support, enabling the team to push forward.
Our team is investing deeply to optimize how generative AI and traditional machine learning systems intersect. Interested in helping us advance the frontier? Our machine learning teams are hiring!
Instacart
Author
Instacart is the leading grocery technology company in North America, partnering with more than 1,800 national, regional, and local retail banners to deliver from more than 100,000 stores across more than 15,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page.